Περίληψη
Στον ψηφιακό συνδρομητικό βρόχο (digital subscriber loop) που συνδέει τον συνδρομητή με το κέντρο
εμφανίζεται το πρόβλημα των ηλεκτρικών ανακλάσεων (echoes). Συγκεκριμένα, το σήμα από τον έναν συνομιλητή
ανακλάται από το κύκλωμα μετατροπής δισύρματου καλωδίου σε τετρασύρματο και επιστρέφει. Αυτό έχει ως
αποτέλεσμα, το σήμα που λαμβάνει αυτός ο συνομιλητής να μην
περιέχει μόνο το σήμα του δεύτερου συνομιλητή, αλλά και την ανάκλαση του δικού του.
Το πρόβλημα αυτό αντιμετωπίζεται με τη χρήση ενός προσαρμοστικού φίλτρου που ονομάζεται adaptive
echo canceller.
Σε μια σειρά 2 άρθρων παρουσιαστούν 2 προσαρμοστικά φίλτρα που μπορούν να χρησιμοποιηθούν για την υλοποίηση
του echo canceller. Το πρώτο φίλτρο βασίζεται στον αλγόριθμο LMS (Least Mean Squares) και είναι το
αντικείμενο αυτού του άρθρου. Το δεύτερο προσαρμοστικό φίλτρο στηρίζεται στον αλγόριθμο RLS
(Recursive Least Squares) και θα παρουσιαστεί σε επόμενο άρθρο. Τα προσαρμοστικά αυτά φίλτρα θα υλοποιηθούν σε περιβάλλον
MATLAB και θα παρουσιαστούν οι σχετικοί κώδικες, μαζί με τα αποτελέσματα εφαρμογής τους πάνω σε ένα
σήμα φωνής δειγματοληπτημένο σε συχνότητα 8kHz με κβαντισμό των 8 bits ανά δείγμα.
Προαπαιτούμενα
Ο βαθμός δυσκολίας του άρθρου είναι αυξημένος. Για την κατανόηση απαιτούνται βασικές γνώσεις σε γραμμική
άλγεβρα και υψηλή εξοικίωση με έννοιες από την θεωρία σημάτων και συστημάτων καθώς και την ψηφιακή
επεξεργασία σήματος. Επίσης, απαιτούνται γνώσεις MATLAB για την κατανόηση των υλοποιήσεων
των φίλτρων.
Γενικά
Στον ψηφιακό συνδρομητικό βρόχο (digital subscriber loop) που συνδέει τον συνδρομητή με το κέντρο
εμφανίζεται το πρόβλημα των ηλεκτρικών ανακλάσεων (echoes). Συγκεκριμένα, το σήμα από το συνομιλητή
1 (Speaker 1), ανακλάται από το κύκλωμα μετατροπής δισύρματου καλωδίου σε τετρασύρματο (κύκλωμα
Hybrid) και επιστρέφει. Αυτό έχει ως αποτέλεσμα, το σήμα που λαμβάνει ο συνομιλητής 1 να μην
περιέχει μόνο το σήμα του δεύτερου συνομιλητή, x2(n), αλλά και την ανάκλαση του δικού του.
Το πρόβλημα αυτό αντιμετωπίζεται με τη χρήση ενός προσαρμοστικού φίλτρου που ονομάζεται adaptive
echo canceller, όπως φαίνεται στο Σχήμα 1.
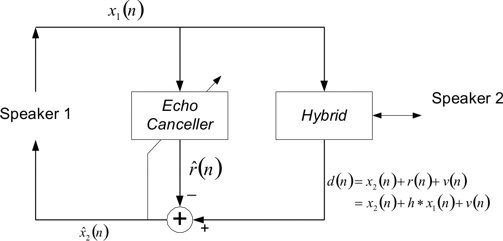
Σχήμα 1.
Στο παραπάνω σχήμα η ακολουθία x1(n) περιλαμβάνει τα δείγματα της φωνής του ομιλητή
στο Speaker 1, η ακολουθία x2(n) τα δείγματα της φωνής του δεύτερου ομιλητή στο Speaker 2,
v(n) είναι ο λευκός Gaussian θόρυβος μηδενικής μέσης τιμής και διασποράς σν2 = 0.03
που υπεισέρχεται στο σύστημα και τέλος r(n) = h * x1(n) είναι η ανάκλαση της φωνής του
πρώτου ομιλητή που επιστρέφει ξανά σε αυτόν.
Αυτό που γίνεται προσπάθεια να επιτευχθεί με την χρήση του προσαρμοστικού φίλτρου είναι να
αναιρεθεί η ηχώ που λαμβάνει ο ομιλητής στο Speaker 1, δημιουργώντας ένα αντίγραφο της που θα
αφαιρεθεί από το λαμβανόμενο σήμα. Αν δεν υπήρχε ο echo canceller τότε ο ομιλητής στο Speaker 1 θα
λάμβανε ουσιαστικά το σήμα : d(n) = x2(n) + h * x1(n) + v(n) . Mε την χρήση
του echo canceller αυτό που λαμβάνει είναι το σήμα σφάλματος e(n) = x2'(n) = x2(n)
+ h * x1(n) + v(n) - h' * x1(n), οπότε στην περίπτωση που το προσαρμοστικό φίλτρο
λειτουργήσει ικανοποιητικά ο παράγοντας h * x1(n) - h' * x1(n) ουσιαστικά θα
εξαλειφθεί και πλέον ο ομιλητής θα λαμβάνει μόνο το σήμα της φωνής του συνομιλητή του (μαζί με κάποιον
θόρυβο εννοείται).
Η υλοποίηση του προσαρμοστικού φίλτρου θα γίνει χρησιμοποιώντας τον αλγόριθμο LMS
(Least Mean Square). Στο αρχείο echo.mat
μπορείτε να βρείτε το σήμα φωνής του συνομιλητή 1, x1, και το σήμα φωνής d που αυτός
λαμβάνει πριν τον echo canceller. Η precompiled ρουτίνα sq_error.p
(αν η έκδοση του MATLAB που διαθέτετε είναι από την 5.3 και κάτω χρησιμοποιήστε το αρχείο
sq_error2.p) μπορεί να χρησιμοποιηθεί με είσοδο την εκτιμούμενη
ακολουθία x2 για να δώσει ως έξοδο την ακολουθία του στιγμιαίου τετραγωνικού σφάλματος
e(n).
Να σημειωθεί ότι για την
υλοποίηση των φίλτρων έχει χρησιμοποιηθεί το πρόγραμμα MATLAB στην έκδοση 5.3.
Υλοποίηση Echo Canceller με Βάση τον Αλγόριθμο LMS
Αν συμβολίσουμε με r(n) την ηχώ (r(n) = h * x1(n)) και με r'(n) το αντίγραφο της ηχούς
(r'(n) = h' * x1(n)), τότε η συνάρτηση σφάλματος που προσπαθεί να ελαχιστοποιήσει ο
προσαρμοστικός ακυρωτής είναι η :
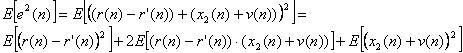
Επειδή το σήμα x2(n) + v(n) είναι ασυσχέτιστο τόσο με την ηχώ όσο και με το αντίγραφο
- εκτίμηση της, ο δεύτερος όρος της παραπάνω εξίσωσης είναι μηδενικός, άρα τελικά :
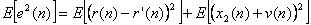
Από την παραπάνω εξίσωση φαίνεται ότι η ελαχιστοποίηση του σφάλματος e2(n) ισοδυναμεί
με την ελαχιστοποίηση του σφάλματος (r(n) - r'(n))2.
Για να υλοποιηθεί το προσαρμοστικό φίλτρο στην παρούσα φάση θα χρησιμοποιηθεί ο αλγόριθμος LMS.
O αλγόριθμος LMS έχει ως εξής :
LMS αλγόριθμος για ένα p - τάξης FIR προσαρμοστικό φίλτρο
|
|
Παράμετροι Εισόδου : | p : τάξη φίλτρου
μ : μέγεθος βήματος
x : ακολουθία δειγμάτων εισόδου
d : επιθυμητή ακολουθία δειγμάτων εξόδου |
|
Αρχικοποίηση : | w0 = 0 |
|
Yπολογισμός : | for n = 1,2,...
y(n) = wnTx(n)
e(n) = d(n) - y(n) |
|
H ρουτίνα που ακολουθεί, υλοποιεί το ζητούμενο προσαρμοστικό φίλτρο με βάση τον αλγόριθμο LMS
όπως περιγράφηκε ανωτέρω :
function [e,w] = echocanceller_lms(xin,d,order,step)
%Συνάρτηση υλοποίησης adaptive echo canceller με χρήση του αλγορίθμου LMS
%
%Είσοδοι : ακολουθία εισόδου xin (x1 στο σχήμα της εκφώνησης)
% ακολουθία d(n) (= x2+r+v)
% τάξη φίλτρου (order)
% step size LMS αλγορίθμου (step)
%Έξοδοι : σήμα σφάλματος e(n)
% πίνακας w με την πορεία των διανυσμάτων των συντελεστών του φίλτρου
limit = size(d,1);
%Αρχικοποίηση διανύσματος συντελεστών
w = zeros(order,limit);
for n=1:limit
%Κατασκευή του διανύσματος xp(n)
for k=1:order
if ((n-k+1) < 1)
xp(k,1) = 0;
else
xp(k,1) = xin(n-k+1);
end
end
%Υπολογισμός της εξόδου του φίλτρου
y(n) = w(:,n)'*xp;
%Υπολογισμός του σφάλματος
e(n,1) = d(n)-y(n);
%Ανανέωση των συντελεστών του φίλτρου
w(:,n+1) = w(:,n) + step*e(n,1)*xp;
end
|
O LMS αλγόριθμος καλείται με αναδρομικό τρόπο να προσεγγίσει τη βέλτιστη λύση Wiener :
woptimal = Rx-1 rdx
όπου Rx είναι ο πίνακας αυτοσυσχέτισης του σήματος x(n) και rdx το διάνυσμα
ετεροσυσχέτισης των x(n) και d(n).
H σύγκλιση του αλγορίθμου υπό την έννοια της μέσης τιμής ορίζει ότι η μέση τιμή της ακολουθίας
{wn} θα πρέπει να συγκλίνει στη βέλτιστη λύση :
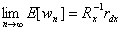
Αν ικανοποιούνται οι υποθέσεις ότι οι διαδικασίες εισόδου και επιθυμητής εξόδου είναι από κοινού
WSS (Wide Sense Stationary) και ισχύει η υπόθεση ανεξαρτησίας («τα δεδομένα x(n) και το διάνυσμα
συντελεστών του LMS, wn, είναι στατιστικά ανεξάρτητα») τότε ισχύει το θεώρημα :
Για από κοινού WSS διαδικασίες, ο αλγόριθμος LMS συγκλίνει υπό την έννοια της
μέσης τιμής αν
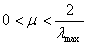
και ικανοποιείται η υπόθεση της ανεξαρτησίας.
Το πρόβλημα με τα παραπάνω είναι ότι η υπόθεση της ανεξαρτησίας ισχύει προσεγγιστικά καθότι το
διάνυσμα των τρεχόντων δεδομένων έχει (έστω και μικρή) συνεισφορά στον υπολογισμό του τρέχοντος
διανύσματος συντελεστών. Για τούτο η επιλογή μιας τιμής για το μέγεθος βήματος του αλγορίθμου
(παράμετρος μ) που να είναι κοντά στο άνω όριο του παραπάνω θεωρήματος, μπορεί να οδηγήσει τον
αλγόριθμο σε απόκλιση.
Επίσης υπάρχει και άλλο ένα ζήτημα. Το όριο που αναφέρθηκε εξασφαλίζει σύγκλιση των συντελεστών
υπό την έννοια της μέσης τιμής. Αυτό δεν αποκλείει την περίπτωση μετά από κάποιο αριθμό επαναλήψεων
να έχουμε σύγκλιση κατά την μέση τιμή, αλλά η διασπορά της ακολουθίας των συντελεστών να είναι
μεγάλη (να παρουσιάζονται δηλαδή μεγάλες διακυμάνσεις γύρω από τη βέλτιστη μέση τιμή).
Για τους λόγους αυτούς είναι ανάγκη να χρησιμοποιηθεί κάποιο αυστηρότερο όριο για το μέγεθος βήματος
του αλγορίθμου. Για τον πίνακα αυτοσυσχέτισης της διαδικασίας εισόδου ισχύει ότι είναι συμμετρικός
και θετικά ορισμένος. Αυτό συνεπάγεται ότι οι ιδιοτιμές του είναι θετικές και επίσης ισχύει ότι :
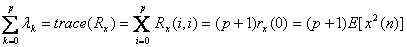
Θα ισχύει ότι :
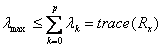
Έτσι μπορεί να προκύψει ένα αυστηρότερο άνω όριο για την παράμετρο μ :
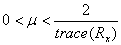
Η σχέση αυτή προσφέρει και ένα επιπλέον σημαντικό πλεονέκτημα. Χρησιμοποιώντας τη, εξασφαλίζεται
σύγκλιση υπό την έννοια του μέσου τετραγώνου και όχι μόνο υπό την έννοια της μέσης τιμής. Αυτό
σημαίνει ότι η ακολουθία των συντελεστών όχι μόνο θα έχει ως μέση τιμή τη βέλτιστη λύση αλλά και η
διακύμανση της γύρω από τη μέση τιμή θα είναι φραγμένη.
Με βάση όσα αναφέρθηκαν για να υπολογιστεί το άνω όριο του step size του LMS αλγορίθμου, πρέπει
να υπολογιστεί το trace του πίνακα αυτοσυσχέτισης του σήματος εισόδου. Ο πίνακας αυτοσυσχέτισης για
το σήμα εισόδου ορίζεται ως εξής :
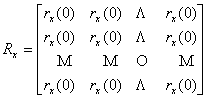
όπου rx(k-l) = E[x(n-k) x(n-l)].
H ρουτίνα που ακολουθεί υπολογίζει τον πίνακα αυτοσυσχέτισης και στη συνέχεια επιστρέφει το trace
του :
function tr = trace_calc(input,order)
%Συνάρτηση υπολογισμού του ίχνους του πίνακα αυτοσυσχέτισης της διαδικασίας input
%
%Είσοδοι : input - σήμα του οποίου τον πίνακα αυτοσυσχέτισης πρέπει να υπολογίσουμε
% order - τάξη του πίνακα αυτοσυσχέτισης
%Έξοδος : tr - το ίχνος (trace) του πίνακα αυτοσυσχέτισης του σήματος input
%Yπολογισμός των συντελεστών rx
factor = 1/size(input,1);
for k=0:order
rx(k+1) = 0;
for l=(k+1):size(input,1)
rx(k+1) = rx(k+1) + (input(l)*input(l-k));
end
rx(k+1) = rx(k+1)*factor;
end
%Κατασκευή του πίνακα αυτοσυσχέτισης (λαμβάνοντας υπόψη τις ιδιότητες του)
Rx = toeplitz(rx(1:(size(rx,2)-1)));
%Υπολογισμός του trace του πίνακα Rx
tr = trace(Rx);
|
Ανάλογα με το πλήθος των συντελεστών που θα χρησιμοποιηθεί, προκύπτουν τα ακόλουθα άνω όρια για
την παράμετρο step size του LMS :
| Πλήθος Συντελεστών |
trace(Rx) |
Άνω Όριο Step Size |
| 2 |
126.7066 |
0.0158 |
| 4 |
253.4131 |
0.0079 |
| 6 |
380.1197 |
0.0054 |
| 8 |
506.8263 |
0.0039 |
| 10 |
633.5328 |
0.0032 |
| 12 |
760.2394 |
0.0026 |
| 14 |
886.9460 |
0.0023 |
Για πλήθος συντελεστών 2, 4, 6, 8, 10, 12 και 14 εξετάζεται η συμπεριφορά του αλγορίθμου για
διάφορες τιμές της παραμέτρου μ. Πιο συγκεκριμένα εξετάζονται διάφορες τιμές του μ από 0.1 μέχρι
10-7. Η ρουτίνα που ακολουθεί υλοποιεί την διαδικασία αυτή αυτόματα :
function e = doit_lms(xin,d)
%Ο υπολογισμός θα γίνει για πλήθος συντελεστών 2,4,6,8,10,12,14 και για step sizes
%0.1, 0.01, 0.001, 0.0001, 0.00001, 0.000001, 0.0000001
n = 1;
for order = 2:2:14
step = 0.1;
while step >= 0.0000001
e(:,n) = echocanceller_lms(xin,d,order,step);
step = step/10;
n = n+1;
end
|
Για να αξιολογηθούν τα αποτελέσματα που προέκυψαν ακουστικά, μπορεί να χρησιμοποιηθεί η συνάρτηση
sound του
MATLAB. Κατ' αρχήν για τιμές του step size 10-1 και 10-2 δεν ακούγεται τίποτα,
ανεξάρτητα από το πλήθος
των συντελεστών. Μόνο για πλήθος συντελεστών 2 και step size = 10-2 ακούγεται στην αρχή
κάτι σαν πολύ έντονο θόρυβος και στην συνέχεια τίποτα. Κοιτώντας τις τιμές των δειγμάτων της
ακολουθίας e(n) (ή x2'(n) όπως συμβολίζεται στο σχήμα) μπορεί να παρατηρηθεί ότι αυτές
στα πρώτα δείγματα περιλαμβάνουν κάποιες τιμές (οι περισσότερες μηδενικά ή πολύ κοντά στο μηδέν) και
από ένα σημείο και μετά είναι όλες NaN.
Για τούτο και στην αρχή ακούγεται σαν μια πολύ μικρής διάρκειας ιψύσυχνη νότα και στην συνέχεια
τίποτα. Είναι φανερό λοιπόν ότι στις περιπτώσεις αυτές ο αλγόριθμος αποκλίνει.
Παρατηρείστε στο πίνακα που παρατίθεται παραπάνω με τα άνω όρια για το step size του αλγορίθμου
ότι σε όλες τις περιπτώσεις (εκτός από εκείνη για 2 συντελεστές) το άνω όριο είναι μικρότερο του
10-2. Για τούτο και είναι φυσικό ο αλγόριθμος να αποκλίνει. Παρόλα αυτά ακόμα και στην
περίπτωση όπου χρησιμοποιείται φίλτρο με 2 συντελεστές ο αλγόριθμος και πάλι αποκλίνει, κάτι που
οδηγεί
στην σκέψη ότι δεν αρκεί απλώς να επιλεγεί κάποια τιμή για το step size που να είναι απλά μικρότερη
από το άνω όριο. Χρειάζεται η τιμή αυτή να είναι αρκετά μικρότερη. Το πόσο μπορεί να το διαπιστωθεί
στη συνέχεια.
Για μέγεθος βήματος με τιμή 10-3, είμαστε κάτω από το άνω όριο για όλα τα πλήθη
συντελεστών που έχουν υπολογιστεί. Για φίλτρο με 2 συντελεστές το ακουστικό αποτέλεσμα είναι σχετικά
αποδεκτό. Η ηχώ από τον ομιλητή ακούγεται αρκετά, ενώ υπάρχει και πολύς θόρυβος. Παρόλα αυτά ο
κυρίαρχος ήχος που ακούγεται είναι ο ομιλητής από το Speaker 2. Μπορεί να παρατηρηθεί ότι ο
αλγόριθμος χρειάζεται κάποιο χρονικό διάστημα να συγκλίνει καθώς στην αρχή αυτό που ακούγεται είναι
ιδιαίτερα άσχημο αλλά μετά από κάποιο χρονικό σημείο το αποτέλεσμα είναι αρκετά καλύτερο.
Για πλήθος συντελεστών ίσο με 4, αρχικά υπάρχει πάρα πολύ έντονος θόρυβος που καλύπτει τα πάντα,
αλλά από ένα σημείο και μετά αρχίζει να ακούγεται έστω και ένα κακής ποιότητας ηχητικό σήμα.
Αντίθετα για φίλτρα με περισσότερους από 4 συντελεστές το αποτέλεσμα είναι μόνο θόρυβος. Βέβαια ούτε
στην περίπτωση με 4 συντελεστές ούτε και για περισσότερους μπορούμε να θεωρηθεί το αποτέλεσμα
αποδεκτό.
Γιατί συμβαίνει αυτό; Για 2 συντελεστές παρατηρείστε ότι πλέον έχουμε απομακρυνθεί αρκετά από το
άνω όριο για το step size. Άρα είναι αναμενόμενο να αρχίσουν να προκύπτουν κάποια θετικά
αποτελέσματα. Επίσης, αν και όλες οι υπόλοιπες περιπτώσεις φίλτρων έχουν άνω όριο πάνω από το
0.001, η τιμή αυτή είναι σχετικά κοντά στο άνω όριο. Η πιο απομακρυσμένη τιμή είναι αυτή που
αντιστοιχεί σε πλήθος συντελεστών 4 και φάνηκε πως μόνο στη περίπτωση αυτή μπορεί ο αλγόριθμος να
αρχίσει να συγκλίνει μετά από κάποιο χρονικό διάστημα ώστε να προκύψει κάποιο αποτέλεσμα.
Μικραίνοντας και άλλο το step size (10-4 - 10-5), τα αποτελέσματα είναι
πολύ καλύτερα. Σε αυτές τις περιπτώσεις η φωνή της ομιλήτριας 1 ακούγεται λίγο και κυρίως στα
σημεία που ο ομιλητής 2 κάνει παύσεις, στην αρχή και στο τέλος που ομιλητής 2 έχει τελειώσει ενώ ο
1 συνεχίζει. Το κυριότερο πάντως είναι ότι ο ομιλητής 2 είναι η κυρίαρχη φωνή που ακούγεται και
μάλιστα ακούγεται και με σχετικά πολύ καλή ευκρίνεια. Μπορεί να παρατηρηθεί ότι βασικά σχεδόν τα
ίδια αποτελέσματα προκύπτουν για όλα τα φίλτρα από 4 συντελεστές και πάνω.
Αντίθετα για φίλτρα με ίδιο πλήθος συντελεστών αλλά ακόμα μικρότερο step size το αποτέλεσμα δεν
είναι και τόσο ικανοποιητικό. Ο αλγόριθμος αργεί πολύ να συγκλίνει με αποτέλεσμα στην αρχή να
ακούγεται κυρίως ο ομιλητής 1 και μετά την πάροδο κάποιου χρονικού διαστήματος να αρχίσει να
ακούγεται ο ομιλητής 2 πιο δυνατά και καθαρά ώστε να υπερκαλύπτει τον ομιλητή 1.
Έτσι, παρατηρείται τελικά ότι οι τιμές για το step size για τις οποίες εμφανίζονται καλά
αποτελέσματα είναι οι τιμές 10-4 και 10-5. Χρησιμοποιώντας τις τιμές αυτές
γίνεται εμφανές ότι επιτυγχάνεται η απαραίτητη σύγκλιση του αλγορίθμου (που ακουστικά μεταφράζεται
σε ένα ηχητικό σήμα όπου βασικά αποκόπτεται η ηχώ του ομιλητή 1), και σε αποδεκτό χρονικό διάστημα.
Μικρότερες τιμές οδηγούν είτε σε απόκλιση είτε σε άσχημα ηχητικά αποτελέσματα, ενώ μεγαλύτερες
τιμές καθυστερούν πολύ την σύγκλιση με αποτέλεσμα να μην προλαβαίνει το σύστημα να αντιμετωπίζει
την επίδραση της ηχούς. Τελικά αυτό που παρατηρείται είναι ότι χρησιμοποιώντας step size κοντά στο
θεωρητικό άνω όριο είτε υπάρχει ο κίνδυνος να αποκλίνει ο αλγόριθμος είτε το αποτέλεσμα που
προκύπτει δεν είναι καλό. Αντίθετα όσο μικρότερο step size επιλεγεί, τόσο περισσότερο σίγουρος μπορεί
να είναι κάποιος ότι τελικά ο αλγόριθμος θα συγκλίνει. Το θέμα όμως είναι ότι το κόστος για μικρό
step size είναι ο χρόνος που απαιτείται ώστε να συγκλίνει ο αλγόριθμος. Το πρόβλημα που εμφανίζεται
με το συγκεκριμένο παράδειγμα είναι ότι η σύγκλιση αργεί τόσο να έρθει ώστε η ηχώ να μην
εξουδετερώνεται αποτελεσματικά. Στη γενικότερη περίπτωση το πρόβλημα που θα εμφανίζεται είναι ότι
το φίλτρο δεν θα εμφανίζει καλά χαρακτηριστικά ως προς το trackability (δηλαδή την ικανότητα του να
παρακολουθεί τις αλλαγές του σήματος και να προσαρμόζεται γρήγορα σε αυτές).
Ένας πιο μαθηματικό τρόπος μπορεί να χρησιμοποιηθεί για να επιβεβαιωθούν οι επιλογές που έχουν
αναφερθεί ως καλύτερες. Με την χρήση της ρουτίνας που παρέχεται (sq_error2) υπάρχει η δυνατότητα
δίνοντας ως είσοδο την εκτιμούμενη ακολουθία e(n), να ληφθεί το στιγμιαίο τετραγωνικό σφάλμα
εκτίμησης. Από αυτό μπορεί να εξαχθεί η μέση τιμή και να προκύψουν σχετικά συμπεράσματα. Ο παρακάτω
πίνακας δείχνει το μέσο τετραγωνικό σφάλμα που προκύπτει σε κάθε περίπτωση :
| |
step size 10-1 |
step size 10-2 |
step size 10-3 |
step size 10-4 |
step size 10-5 |
step size 10-6 |
step size 10-7 |
| 2 Συντελεστές |
NaN |
NaN |
12.2655 |
5.4620 |
6.3851 |
12.8364 |
32.8590 |
| 4 Συντελεστές |
NaN |
NaN |
1.6712*1013 |
2.7755 |
1.5451 |
5.1749 |
25.2568 |
| 6 Συντελεστές |
NaN |
NaN |
1.6439*1059 |
3.4784 |
1.5544 |
4.6886 |
22.0761 |
| 8 Συντελεστές |
NaN |
NaN |
3.2924*10159 |
4.5042 |
1.6405 |
4.6865 |
21.3361 |
| 10 Συντελεστές |
NaN |
NaN |
2.9945*10291 |
5.6076 |
1.7284 |
4.6176 |
21.2990 |
| 12 Συντελεστές |
NaN |
NaN |
Inf |
6.8658 |
1.8014 |
4.6359 |
21.1341 |
| 14 Συντελεστές |
NaN |
NaN |
NaN |
8.2342 |
1.8876 |
4.6461 |
20.7187 |
Από τον πίνακα αυτόν παρατηρείται ότι πράγματι αυτά που διαπιστώθηκε ακουστικά ισχύει και μάλιστα
τώρα μπορεί να ειπωθεί ότι τελικά το καλύτερο φίλτρο είναι αυτό που έχει 4 συντελεστές και step size
αλγορίθμου ίσο με 10-5.
Στα γραφήματα που ακολουθούν παρουσιάζεται η συμπεριφορά του αλγορίθμου για διαφορετικές τιμές του
step size. Γίνονται βασικά δύο απεικονίσεις. Η μία αφορά το στιγμιαίο τετραγωνικό σφάλμα του
αλγορίθμου όπως προκύπτει από την συνάρτηση sq_error2. Η
δεύτερη αφορά το μέσο τετραγωνικό σφάλμα. Ο λόγος που χρησιμοποιείται και η δεύτερη αναπαράσταση
είναι ότι ο αλγόριθμος ουσιαστικά επιζητά την ελαχιστοποίηση του μέσου και όχι του στιγμιαίου
τετραγωνικού σφάλματος, οπότε η σύγκλιση μάλλον θα μπορεί να παρατηρηθεί καλύτερα μέσω αυτού, αντί
του στιγμιαίου. Για να παραχθούν οι κατάλληλες τιμές για τα γραφήματα που σχετίζονται με την
απεικόνιση του μέσου τετραγωνικού σφάλματος έχει υλοποιηθεί η ακόλουθη ρουτίνα στο MATLAB :
function meanerror = meanerror_calc(error,method,window_size)
%Συνάρτηση υπολογισμού του μέσου τετραγωνικού σφάλματος.
%Είσοδοι : error : διάνυσμα που περιέχει τα στιγμιαία τετραγωνικά σφάλματα.
% method : string που καθορίζει το πως θα υπολογιστεί το μέσο τετραγωνικό
% σφάλμα. Mπορεί να πάρει τις ακόλουθες τιμές :
% 'mean' :ο υπολογισμός γίνεται χρησιμοποιώντας την μέση τιμή
% όλων των προηγούμενων στιγμιαίων σφαλμάτων
% 'window' :ο υπολογισμός γίνεται χρησιμοποιώντας την μέση τιμή
% των προηγούμενων στιγμιαίων σφαλμάτων που βρίσκονται
% σε ένα χρονικό παράθυρο που καθορίζει ο χρήστης
% window_size :καθορίζει το μέγεθος του παραθύρου που θα χρησιμοποιηθεί.
%Έξοδος : meanerror : το μέσο τετραγωνικό σφάλμα.
methods = {'mean','window'};
str =lower(method);
s = strmatch(str,methods);
if (~isempty(s))
if (s(1) == 1)
%Για τον υπολογισμό του μέσου τετραγωνικού σφάλματος δεν
χρησιμοποιείται
%κάποιο παράθυρο αλλά η τιμή του ισούται με την μέση τιμή όλων των στιγμιαίων
%τετραγωνικών σφαλμάτων των προηγούμενων στιγμών
for n = 1:length(error)
meanerror(n) = mean(error(1:n));
end
else
%Για τον υπολογισμό του μέσου τετραγωνικού σφάλματος χρησιμοποιείται κάποιο
%παράθυρο το μέγεθος του οποίου καθορίζεται από την χρήστη (μεταβλητή εισόδου
%window_size)
for n =1:length(error)
if (n < window_size)
meanerror(n) = mean(error(1:n));
else
meanerror(n) = mean(error((n-window_size+1):n));
end
end
end
else
error(['Invalid input string: ''' method '''.Type : help meanerror_calc , for more info.']);
end
|
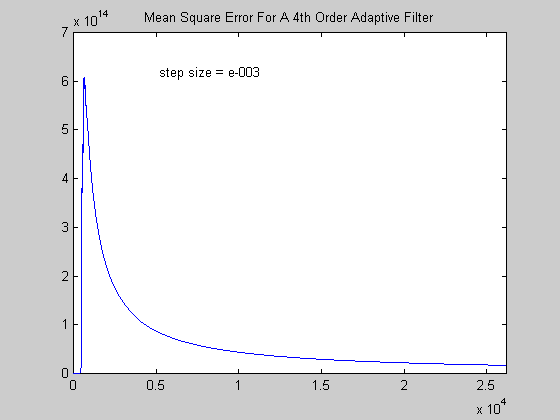
Σχήμα 4.
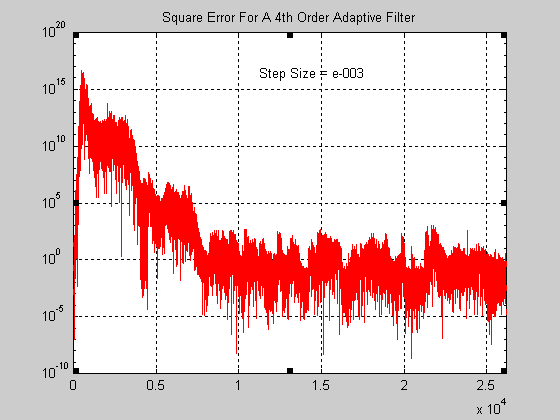
Σχήμα 5.
Το επιλεγμένο step size για την περίπτωση που εικονίζεται παραπάνω (Σχήματα 4 και 5) είναι 10-3 που
είναι μια αποτυχημένη επιλογή σύμφωνα με τις ακουστικές παρατηρήσεις. Προσέξτε στο διάγραμμα πόσο
μεγάλες είναι οι διακυμάνσεις του στιγμιαίου σφάλματος (έχει χρησιμοποιηθεί λογαριθμική κλίμακα
στον κατακόρυφο άξονα). Παρακολουθώντας πάντως την εξέλιξη στο χρόνο του μέσου τετραγωνικού
σφάλματος μπορεί να παρατηρηθεί ότι όντως τείνει να συγκλίνει σε μια τιμή, πράγμα που έγινε αντιληπτό
και ακουστικά όπου στην αρχή (που το μέσο τετραγωνικό σφάλμα είναι πολύ μεγάλο) δεν ακούγεται τίποτα
πέρα από θόρυβο και μετά από κάποιο χρονικό σημείο αρχίζει να διακρίνεται έστω και ένα χαμηλής
ποιότητας ακουστικό σήμα.
Προσέξτε την διαφορά τώρα σε ένα επιτυχημένο φίλτρο :
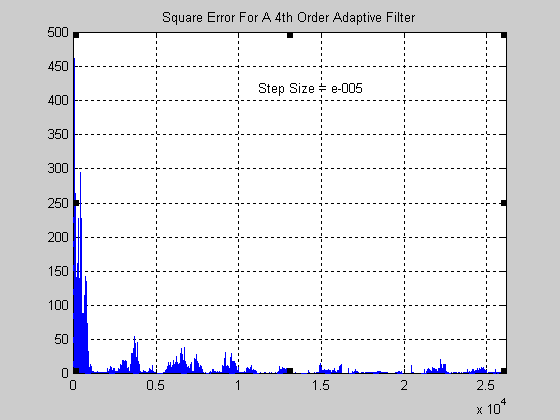
Σχήμα 6.
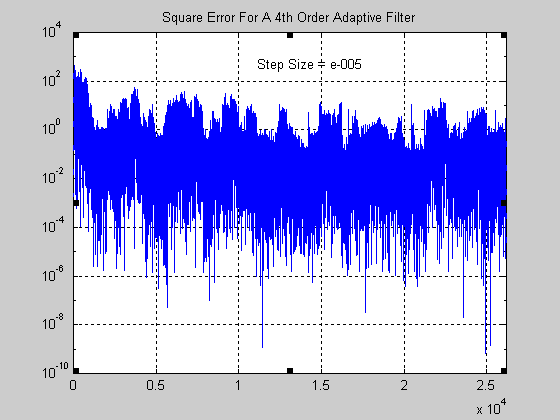
Σχήμα 7.
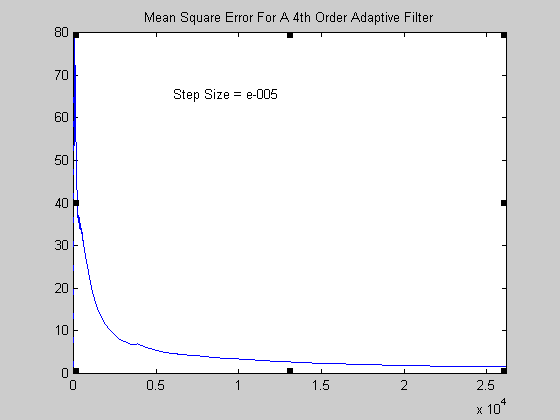
Σχήμα 8.
Η διακύμανση του στιγμιαίου σφάλματος είναι αρκετά μικρότερη (παρατηρείστε στο διάγραμμα όπου ο
κατακόρυφος άξονας είναι σε λογαριθμική κλίμακα την διαφορά ανάμεσα σε αυτό και το προηγούμενο
διάγραμμα). Επίσης το μέσο τετραγωνικό σφάλμα που ενδιαφέρει βασικά (εφόσον ουσιαστικά σύγκλιση
ως προς αυτό επιθυμούμε και όχι προς το στιγμιαίο) παρατηρείστε ότι συγκλίνει σε (πολύ) μικρότερη
τιμή και επίσης το εμβαδό μεταξύ της καμπύλης και του οριζόντιου άξονα είναι πολύ μικρότερο, πράγμα
που μεταφράζεται στην καλύτερη ποιότητα του ήχου που ακούμε και στην αποτελεσματικότητας της
απομάκρυνσης της ηχούς που εμφανίζει το φίλτρο αυτό.
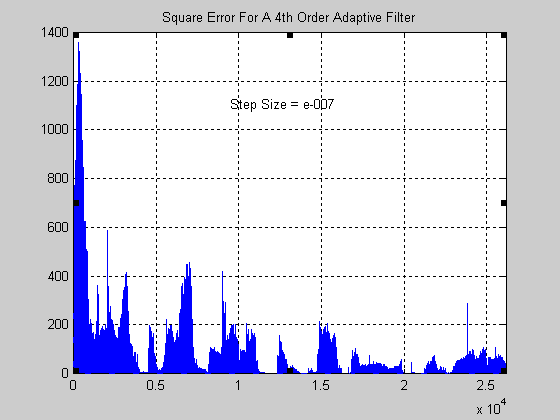
Σχήμα 9.
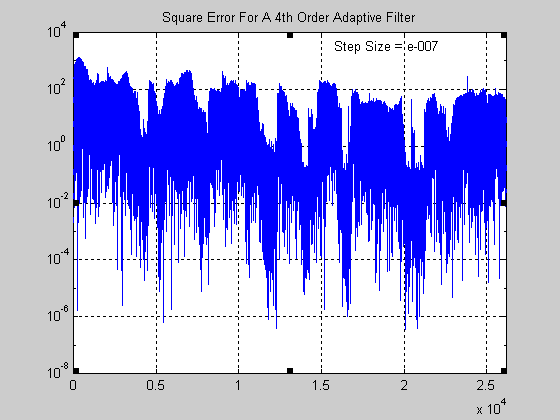
Σχήμα 10.
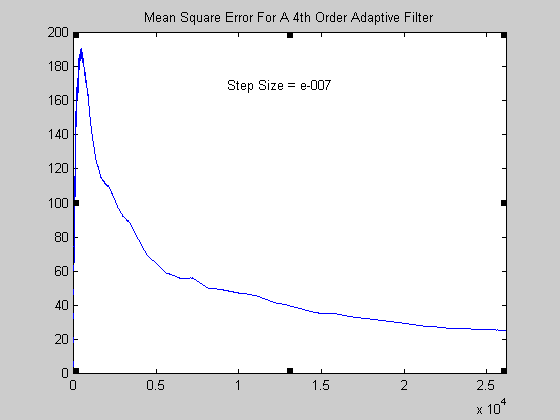
Σχήμα 11.
Στην περίπτωση του φίλτρου με step size 10-7 παρατηρείστε πόσο πολύ αργεί η σύγκλιση
σε σχέσης με τα άλλα δύο φίλτρα. Ουσιαστικά μπορεί να ειπωθεί ότι δεν έχει προλάβει να συγκλίνει
και για τούτο το αποτέλεσμα που παρουσιάζεται δεν είναι ικανοποιητικό.
Χρήσιμο τέλος είναι να παρουσιαστεί και η πορεία του μέσου τετραγωνικού σφάλματος για τα
διαφορετικά step sizes σε ένα κοινό γράφημα (υπόψη ότι η κλίμακα στον κατακόρυφο άξονα είναι
λογαριθμική) :
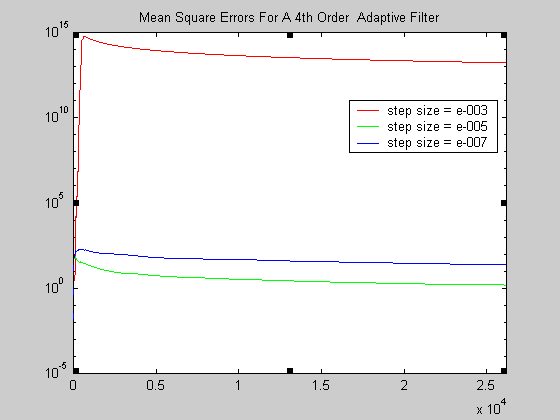
Σχήμα 12.
Καλό είναι να γίνει και μια τελευταία παρατήρηση. Στην αρχή το φίλτρο όταν δουλεύει είναι φυσικό
είτε έχει γίνει μια καλή επιλογή για το step size είτε μια κακή, να παράγει κάποια πολύ μεγάλα
σφάλματα. Τα σφάλματα αυτά επειδή είναι πολύ μεγάλα μπορούν να έχουν και πολύ μεγάλη επίδραση στον
υπολογισμό του μέσου τετραγωνικού σφάλματος κάθε στιγμή, οπότε στις τιμές που μπορούν να παρατηρηθούν
στα γραφήματα να φαίνεται προς το τέλος να είναι το σφάλμα πολύ μεγάλο ενώ στην πράξη τα σφάλματα
να είναι μικρά. Για τούτο καλό είναι να χρησιμοποιήσουμε κάποιο παράθυρο εξομάλυνσης (π.χ. 200
δειγμάτων) και μετά να κάνουμε την σχετική γραφική παράσταση. Στην ρουτίνα, ο κώδικας της οποίας
έχει παρατεθεί παραπάνω, προβλέπεται και η παραγωγή των σχετικών τιμών ώστε να μπορούν να παραχθούν
γραφήματα με ότι παράθυρο κρίνεται επιθυμητό. Στο γράφημα που ακολουθεί έχει χρησιμοποιηθεί
παράθυρο 200 δειγμάτων :
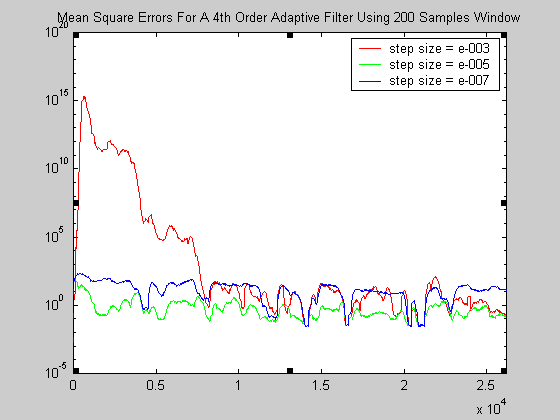
Σχήμα 13.
Πέρα από το γράφημα αυτό, ενδιαφέρον έχει να δειχθεί και η ποιότητα της σύγκλισης. Η είσοδος του
προσαρμοστικού φίλτρου του echo canceller είναι d(n) = x2(n) + r(n) + v(n), όπου x2(n)
είναι το σήμα του ομιλητή 2, r(n) είναι η ανάκλαση του σήματος του ομιλητή 1 και v(n) είναι ο θόρυβος
(λευκός Gaussian θόρυβος μηδενικής μέσης τιμής και διασποράς σν = 0.03). Ασυμπτωτικά,
λοιπόν, το καλύτερο που θα μπορούσε να πετύχει το φίλτρο θα ήταν να αποκόψει τελείως τον παράγοντα
r(n). Τότε το μέσο τετραγωνικό σφάλμα θα έτεινε στην τιμή 0.03 που θα αντιστοιχούσε στο σφάλμα που
προκύπτει λόγω του θορύβου για τον οποίο το φίλτρο δεν μπορεί να κάνει κάτι.
Άρα για να παρουσιαστεί ως ένα βαθμό η ποιότητα της σύγκλισης μπορεί να σχεδιαστεί σε ένα γράφημα
το μέσο τετραγωνικό σφάλμα κάθε χρονική στιγμή και να αντιπαρατεθεί σε σχέση με την ισχύ του
θορύβου (για το μέσο τετραγωνικό σφάλμα χρησιμοποιείται διαδικασία ανάλογη με αυτήν που περιγράφηκε
προηγουμένως - χρήση παραθύρου 200 δειγμάτων) :
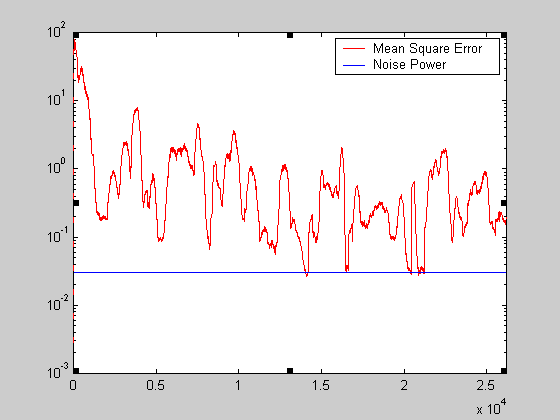
Σχήμα 14.
Τώρα όσον αφορά το πλήθος των συντελεστών που πρέπει να επιλεγεί, μπορεί να παρατηρηθεί ότι από
4 συντελεστές και πάνω το αποτέλεσμα είναι καλό και δεν παρουσιάζει κάποια βελτίωση με την αύξηση
του πλήθους των συντελεστών (τουλάχιστον ακουστικά). Άρα συνυπολογίζοντας και την αύξηση στην
πολυπλοκότητα του φίλτρου που επιφέρει η αύξηση των συντελεστών, η καλύτερη λύση θα ήταν να
επιλεγεί φίλτρο με 4 συντελεστές.
Για την περίπτωση λοιπόν του πιο επιτυχημένου φίλτρου (πλήθος συντελεστών 4, step size 10-5)
σχεδιάζουμε σε ένα γράφημα τη σύγκλιση του διανύσματος των συντελεστών του φίλτρου ως συνάρτηση του
χρόνου. Για να γίνει αυτό και επειδή η σύγκλιση του LMS αλγορίθμου είναι ως προς την μέση τιμή των
συντελεστών (δηλαδή επιθυμούμε η μέση τιμή της ακολουθίας των συντελεστών {wn} να
συγκλίνει στη βέλτιστη λύση), χρησιμοποιούνται στο γράφημα όχι απευθείας οι τιμές των συντελεστών
για κάθε χρονική στιγμή, αλλά ο μέσος όρος των συντελεστών ενός παραθύρου 200 τιμών συντελεστών. Με
αυτόν τον τρόπο μπορεί να παρακολουθηθεί καλύτερα η σύγκλιση δεδομένου και ότι το ηχητικό σήμα δεν
είναι ένα σήμα με σταθερές στατιστικές ιδιότητες.
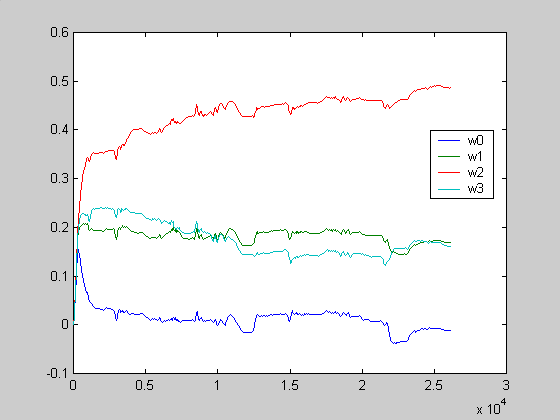
Σχήμα 15.
Καλό θα ήταν πριν ολοκληρωθεί η ανάλυση αυτή να παρουσιαστούν και τα αποτελέσματα με κάποιο πιο
φορμαλιστικό τρόπο ως προς τα ακουστικά αποτελέσματα για να δικαιολογηθούν καλύτερα οι επιλογές που
έχουν γίνει. Αναλύοντας λίγο περαιτέρω το θέμα από ακουστικής πλευράς, μπορεί να γίνει το εξής.
Αυτά που μπορούν να ακουστούν στο MAΤLAB μέσω της συνάρτησης sound(), περνιόνται σε αρχείο .wav
(χρήση συνάρτησης wavwrite() ). Τα .wav αρχεία χρησιμοποιούνται ως είσοδος στο πρόγραμμα WaveStudio
που είναι ένα πρόγραμμα απλοϊκής επεξεργασίας ήχου. Μέσω του προγράμματος αυτού μπορεί να
παρατηρηθεί ότι τα φίλτρα που συγκλίνουν γρήγορα (όπως το προαναφερθέν) παρουσιάζουν καλύτερα
αποτελέσματα στις δοθείσες ακολουθίες γιατί στην αρχή που εμφανίζονται και τα κυριότερα προβλήματα
ο ομιλητής 1 μιλάει πολύ πιο δυνατά από τον ομιλητή 2 και το κυριότερο αργεί να κάνει παύση σε
σχέση με τον ομιλητή 2. Έτσι όταν το φίλτρο δεν μπορεί πολύ γρήγορα να παράγει μια ακολουθία που να
αποσβένει την ανάκλαση, ο ομιλητής 1 ακούγεται πάρα πολύ. Για τούτο και το αποτέλεσμα των φίλτρων
που δεν απέδωσαν καλά, μπορεί να βελτιωθεί αρκετά κάνοντας ένα απλό Fade In για μικρό χρονικό
διάστημα. Επίσης παρατηρώντας στο WaveStudio και τις κυματομορφές σε κάθε περίπτωση, μπορούν να
διαπιστωθούν και τα παραπάνω γραφικά. Μόνο τα πιο επιτυχημένα φίλτρα κατορθώνουν να δώσουν
γραφήματα που να είναι σχετικά ανεξάρτητα του γραφήματος της εισόδου, όπως και θα έπρεπε για μην
έμφανίζεται η έντονη ανάκλαση. Δυστυχώς δεν στάθηκε εφικτό κατά την συγγραφή του παρόντος άρθρου
να εξαχθούν οι κυματομορφές από το WaveStudio για καλύτερα οπτικά αποτελέσματα, αλλά και μέσα από
το MATLAB μπορεί να προκύψει κάτι καλό.
Το γράφημα που ακολουθεί παρουσιάζει την κυματομορφή x1 (σήμα φωνής του ομιλητή 1) :
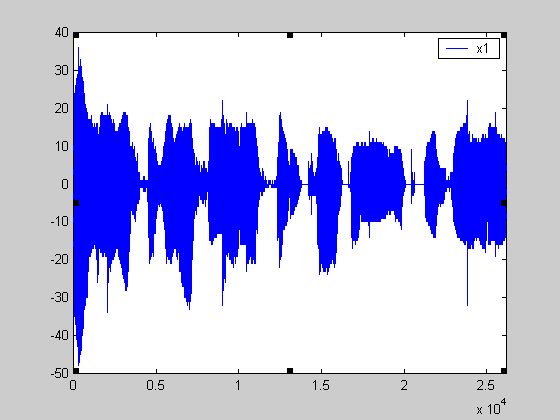
Σχήμα 16.
Παρατηρείστε στο παραπάνω γράφημα πως μεταφράζονται οι ακουστικές παρατηρήσεις που έχουν γίνει
μέχρι τώρα. Στην αρχή για παράδειγμα που αναφέρθηκε ότι ο ομιλητής 1 μιλάει αρκετά δυνατά και χωρίς
παύσεις, αυτό απεικονίζεται με δείγματα μεγάλου πλάτους και χωρίς μηδενισμούς. Οι παύσεις στην
ομιλία είναι τα σημεία εκείνα στα οποία εμφανίζονται μηδενισμοί.
Προσέξτε τώρα πως φαίνεται όταν απεικονιστεί πάνω από αυτήν την κυματομορφή, η κυματομορφή από
ένα επιτυχημένο φίλτρο (για την περίπτωση αυτή θα χρησιμοποιηθεί φίλτρο τάξης 4 με step size 10-4)
και για ένα ανεπιτυχές (για την περίπτωση αυτή θα χρησιμοποιηθεί φίλτρο τάξης 4 με step size 10-7)
:

Σχήμα 17.
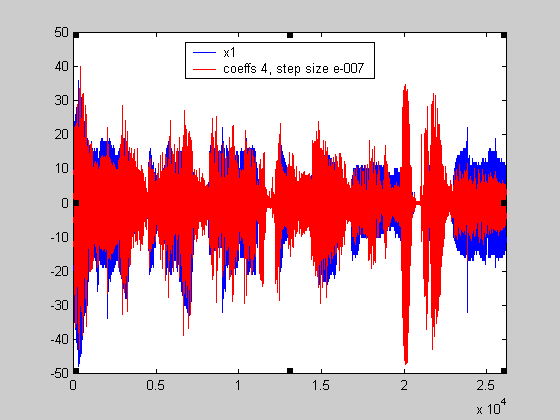
Σχήμα 18.
Παρατηρείστε τι γίνεται για παράδειγμα για τα πρώτα 5000 δείγματα. Στην πρώτη περίπτωση
προκύπτει ένα σχεδόν ασυσχέτιστο σήμα σε σχέση με την x1, πράγμα που δεν ισχύει στην δεύτερη
περίπτωση που είναι απλά σαν να έχει μειωθεί το πλάτος της κυματομορφής.
|
